Part I - The Spark
Chapter 3: The Machine Learns to Read
How prediction became the machine’s first way of noticing

Before the machine could answer, it had to learn the smaller game: what comes next?
The coffee was too hot to…
You probably finished the sentence before you reached this line.
Drink.
You did not open a grammar book. You did not search a database. You did not calculate every possible word that could follow. The sentence simply leaned forward, and some part of you knew where it wanted to go.
This is one of the ordinary miracles of language.
We read by moving ahead of the words. We listen by anticipating what might come next. A sentence does not arrive as a row of dead objects. It arrives with direction. It carries expectation.
A word appears, and already the mind is preparing for another.
Long before ChatGPT could answer questions, write code, summarise papers, or explain itself in careful paragraphs, the machine underneath had to learn a smaller game.
What comes next?
That phrase can sound disappointingly simple. Almost too small for the story of artificial intelligence. It can make a large language model sound like the autocomplete bar above a phone keyboard.
But that comparison breaks quickly.
Prediction is the training objective, not the whole capability. A phone keyboard may suggest the next convenient word from a narrow local context. A large language model is trained on a very different scale, with a very different machine underneath: layers of learned representations, wider context, and enough computation for patterns to become richer than the prompt that began them.
The machine was not handed meaning.
It was given a game.
And the game began to teach it.
What the machine sees
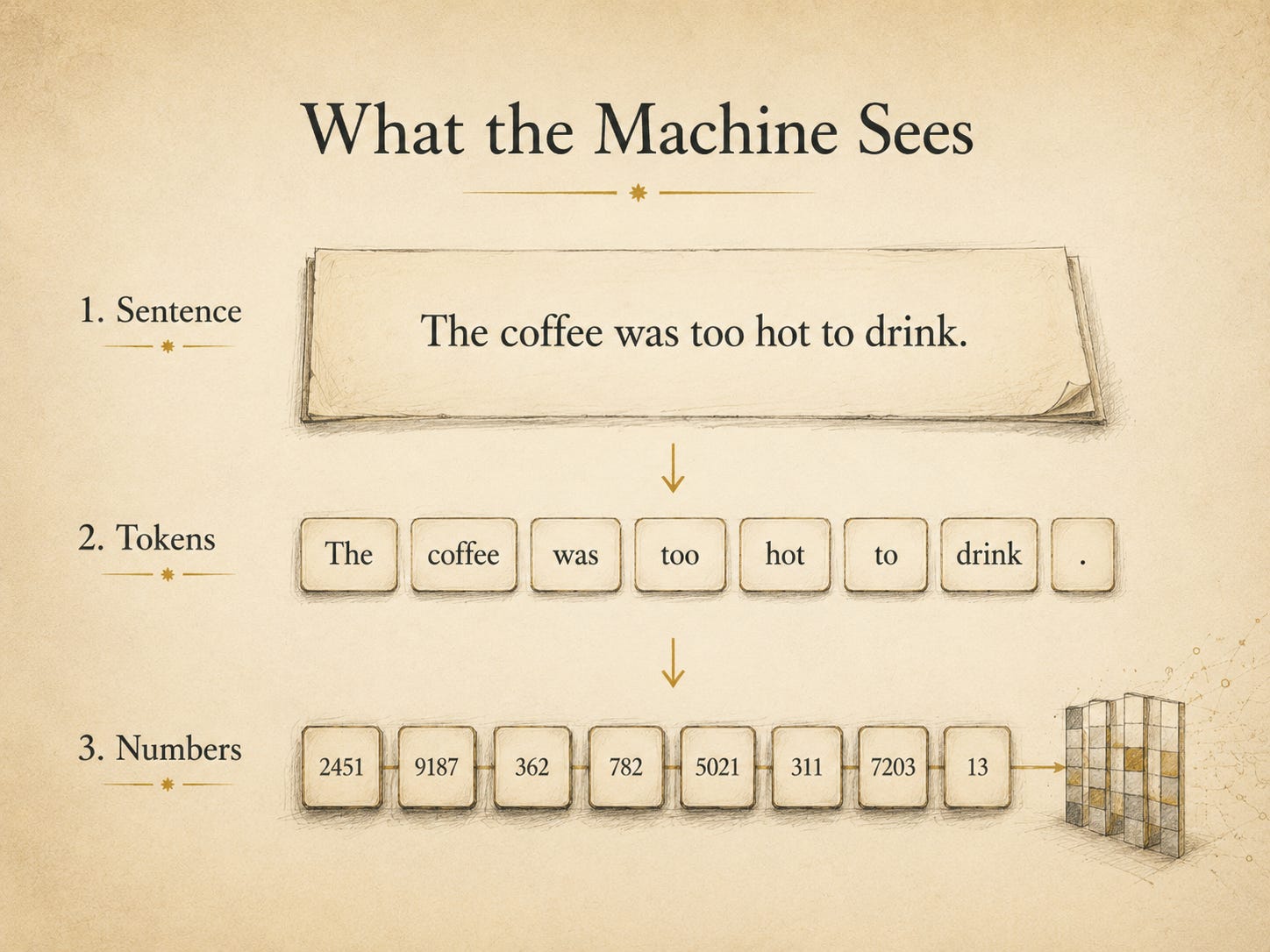
The machine does not begin with meaning. It begins with pieces it can calculate with.
A person sees a sentence.
A machine does not begin there.
Before text can be learned from, it has to be made processable. The sentence is broken into pieces. In modern language models, these pieces are usually called tokens: chunks of text that may be whole words, parts of words, punctuation marks, or other fragments.
The sentence:
The coffee was too hot to drink.
can become a sequence of smaller pieces:
The | coffee | was | too | hot | to | drink | .
Those pieces can then be represented numerically.
This is the first demystification. The machine does not receive language as we do. It does not begin with taste, memory, scene, tone, or experience. It begins with structure.
Then calculation.
Then pattern.
Reading, for the machine, begins as conversion.
The game of what comes next
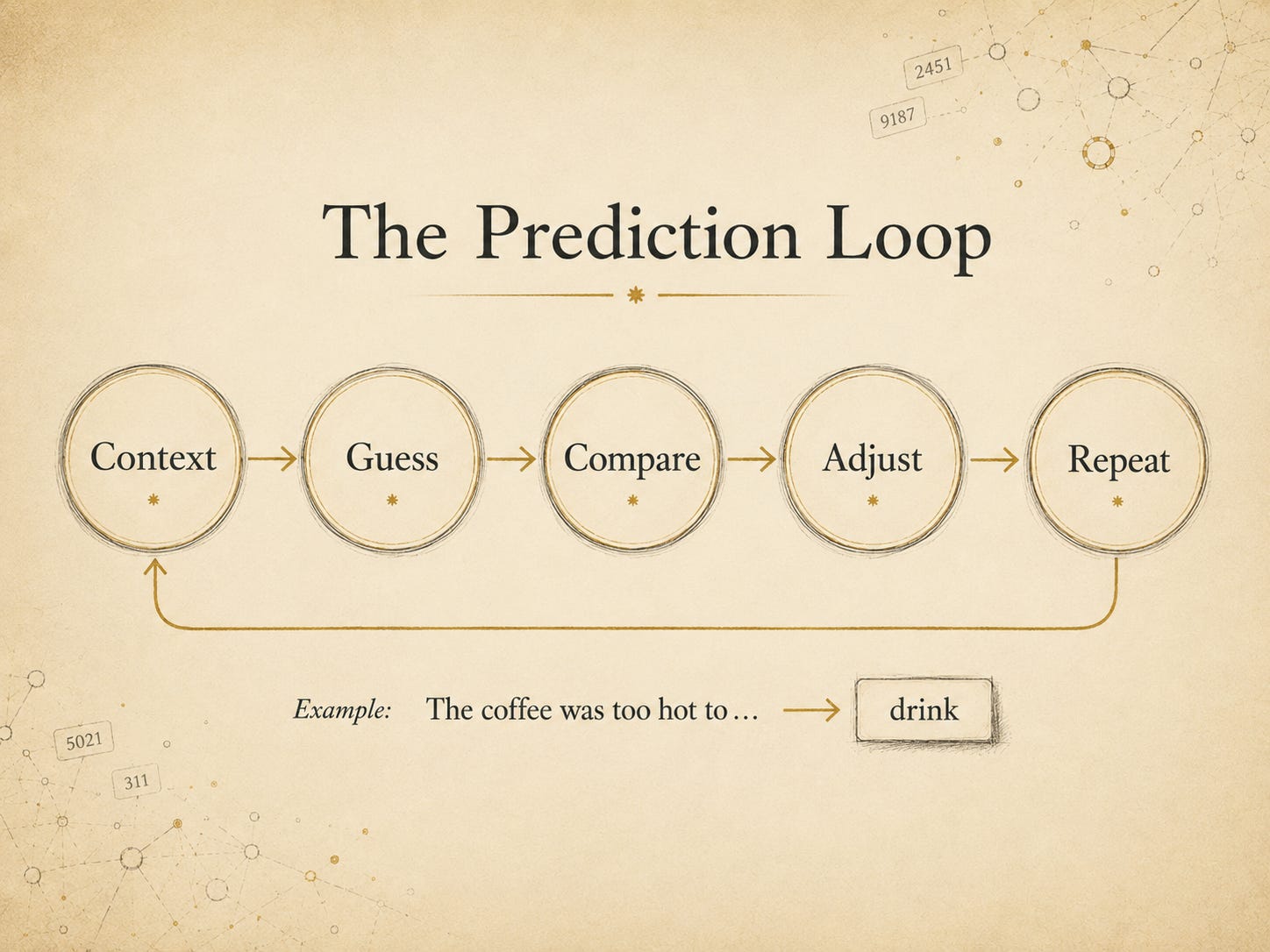
Context → guess → compare → adjust → repeat.
Now give the machine part of a sentence.
The coffee was too hot to ___
The model makes a guess.
Maybe:
drink
During training, the model can compare its guess with the real next token in the text. If the guess is wrong, the system adjusts itself slightly. Then it tries again.
And again.
And again.
A single guess teaches almost nothing.
Billions of guesses begin to shape the machine.
This is the basic idea behind language modelling: train a system on sequences of text so that, given some context, it assigns probabilities to what might come next. The exact details vary across architectures and training methods, but the simple doorway is this:
Given this, what follows?
Why guessing is not small
The cat sat on the…
Mat.
That is the easy version. The version that makes prediction sound like autocomplete.
But language does not stay simple for long.
Try this:
The restaurant was expensive, the waiter was rude, and I will never…
A likely continuation is:
return
To reach that continuation, a model needs more than a nearby word association. It needs signals about the situation: restaurant, complaint, negative tone, future intention, sentence structure.
The next word is not floating alone.
It is pulled by everything before it.
This is where prediction becomes interesting. To predict language well, a model must pick up patterns in language. Some are small: spelling, punctuation, common phrases. Some are larger: topic, tone, sentiment, grammar, code syntax, and argument.
The task is simple.
The pressure created by the task is not.
Prediction can force the machine to learn useful structure.
That is why the phone keyboard comparison only goes so far. A phone keyboard may suggest the next convenient word from a narrow local context. A large language model is trained through prediction until prediction begins to carry structure.

Same surface idea, very different machine underneath.
Meaning becomes geometry
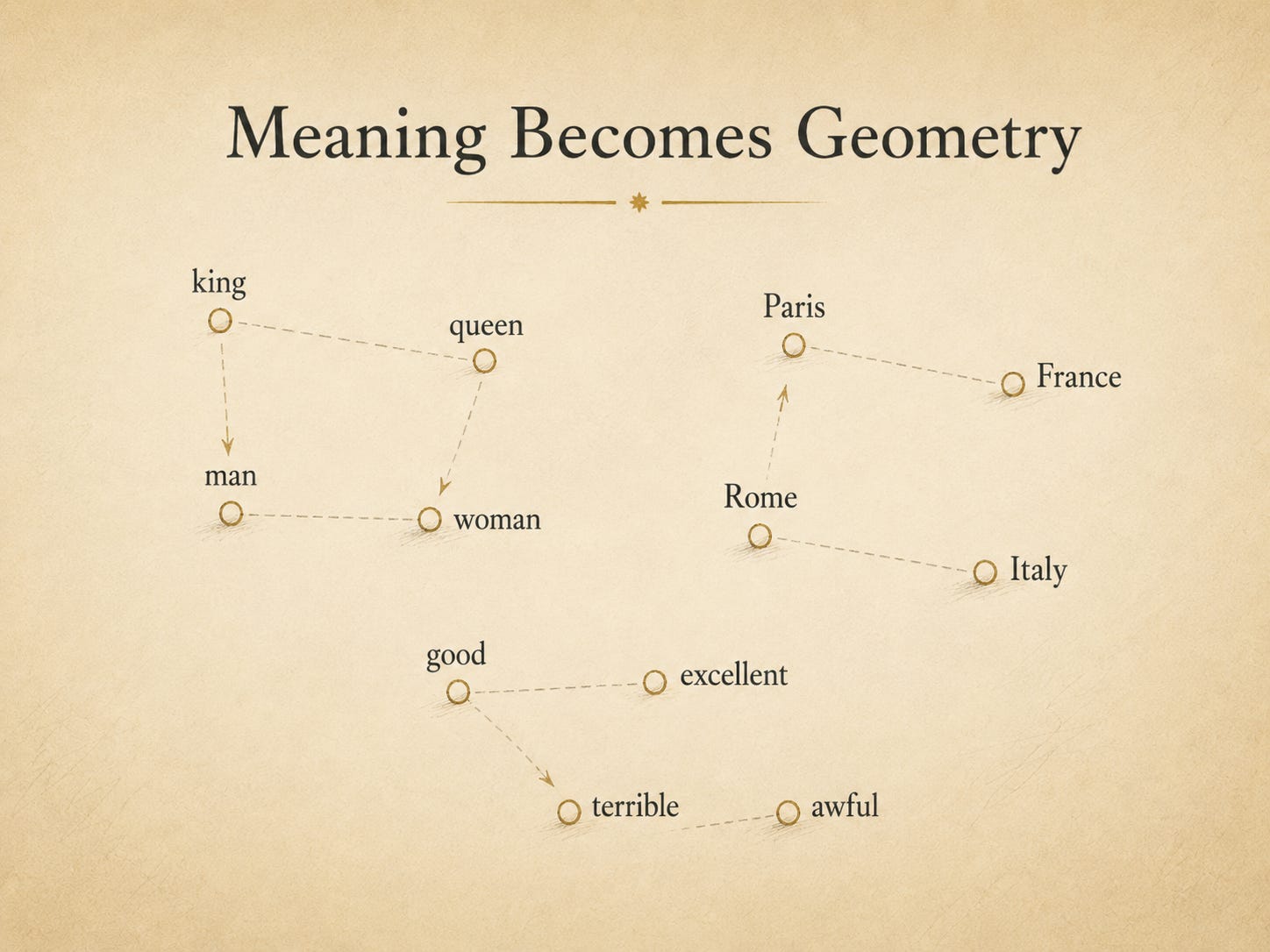
Words begin to live in relation to one another.
There had already been clues that language could become mathematical without becoming meaningless.
Words could be turned into learned numerical forms: representations.
A word could become a vector: a list of numbers that placed it somewhere in a mathematical space. Words used in similar ways could end up closer together. Relationships between words could begin to appear as distances and directions.
The 2013 word2vec paper by Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean proposed two architectures for computing continuous vector representations of words from very large datasets, and evaluated those representations on syntactic and semantic word-similarity tasks. word2vec paper
This is one of those technical ideas that becomes beautiful when seen visually.
King sits near queen.
Paris relates to France.
Rome relates to Italy.
Good drifts closer to excellent than to terrible.
The machine does not know a king the way a child knows a king from stories. It has not stood in Paris. It does not feel goodness.
But inside the mathematics, words can begin to occupy a kind of landscape.
Meaning begins to acquire geometry: a landscape of learned relationships.
The hidden map
The useful thing is not one prediction.
It is what the model builds while learning to predict.
A model is asked to guess what comes next. But to guess better, it must build internal patterns that help it organise what it has seen. Those patterns are not written by hand. They are learned through training.
A model does not read with a body, a history, weather, hunger, shame, or memory.
It learns something narrower: internal representations useful for language tasks.
It can learn that words keep company, that complaints have a shape, that code follows patterns, that questions usually open a space for answers.
The map is what remains after enough guessing and correction.
When the game gets big
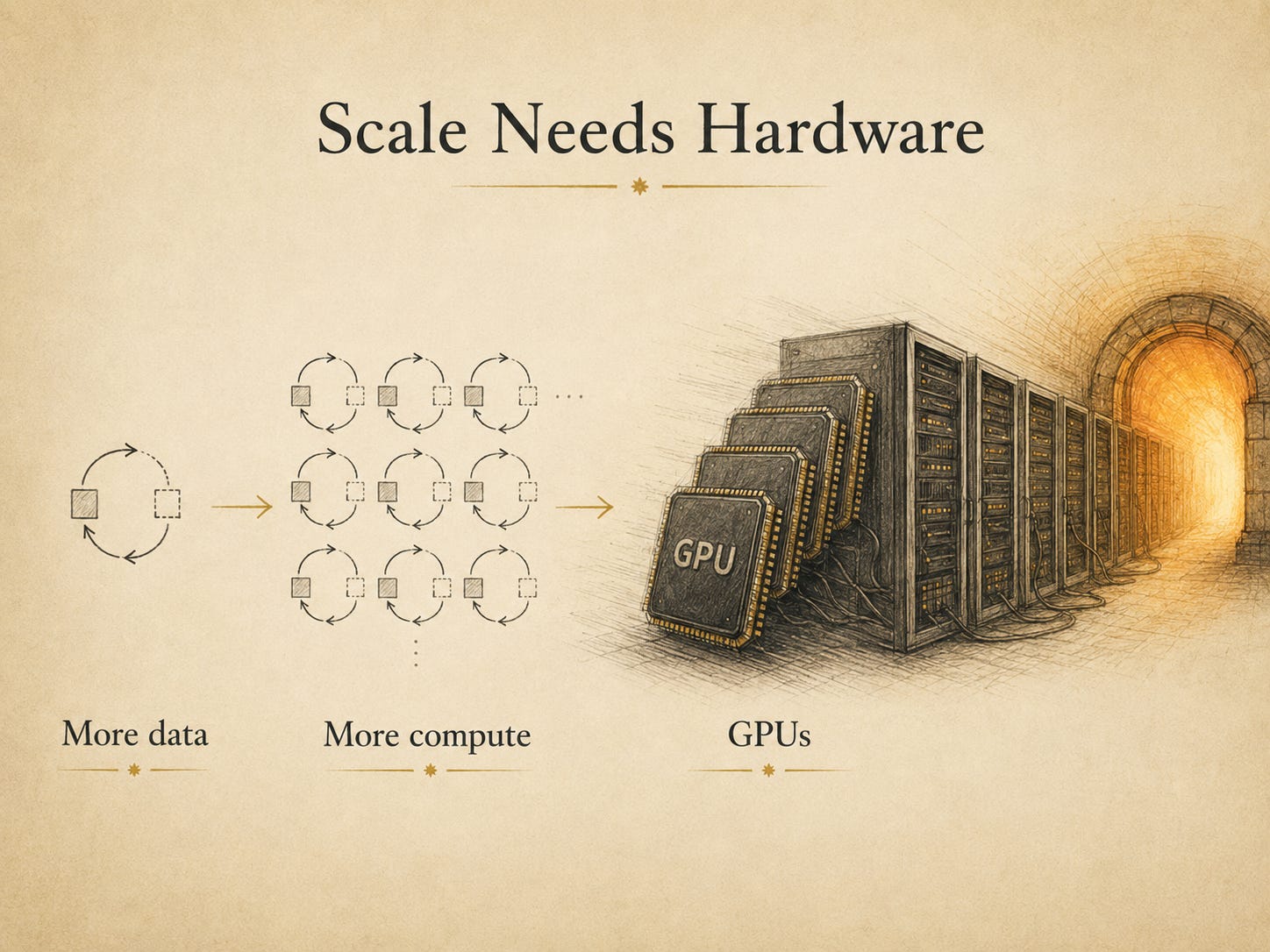
A single prediction is cheap. Training from billions of predictions is not.
The basic loop is easy to draw.
Context.
Guess.
Compare.
Adjust.
Repeat.
But scale changes the meaning of the loop.
Doing this once is trivial. Doing it across huge amounts of text, with large models, over long training runs, becomes a physical problem.
To make the model better, researchers can increase several things: more data, more model capacity, more compute, more training time, better hardware, better infrastructure.
Not always in the same way. Not always with the same returns. But at the frontier, progress increasingly became tied to how much computation could be brought to the training process.
OpenAI’s 2018 analysis, AI and Compute, argued that since 2012 the amount of compute used in the largest artificial intelligence training runs had been increasing exponentially; in the trend it studied, the doubling time was 3.4 months. OpenAI — AI and Compute
Placed beside the simple prediction loop, that number changes the feeling of the story.
The game was simple.
Playing it at the frontier was becoming expensive.
Why hardware enters the story
A graphics processing unit, or GPU, is a chip originally designed to perform many calculations in parallel for graphics.
Deep learning also needs many repeated mathematical operations. That made GPUs useful far beyond their original purpose.
A central processing unit is like a skilled generalist doing complex tasks one after another. A graphics processing unit is more like a large workshop doing many similar calculations at once.
That distinction matters because training a model is not one grand calculation. It is a vast number of smaller calculations repeated again and again.
By 2016, this was already part of OpenAI’s reality. In Infrastructure for Deep Learning, OpenAI described research workloads moving quickly from single-machine experimentation to larger compute needs. One reinforcement-learning experiment went from a single Titan X, to 60 Titan Xs, to nearly 1,600 Amazon Web Services GPUs. OpenAI — Infrastructure for Deep Learning
If prediction is the learning game, compute is what lets the game be played at scale.
The machine did not only need ideas.
It needed hardware.
It needed repetition.
It needed heat.
The heat would become its own story.
The review that carried a feeling

The model was not taught sentiment directly. It learned a signal for it while trying to predict text.
In April 2017, OpenAI published a strange and revealing result.
The work was called Unsupervised Sentiment Neuron.
The system was trained on Amazon reviews. Its task was not to classify reviews as positive or negative. It was not handed sentiment labels in the usual supervised way.
It was trained only to predict the next character in the text.
And yet, inside the model, OpenAI found a strong representation of sentiment. Their post described an unsupervised system that learned an “excellent representation of sentiment” despite being trained only to predict the next character in Amazon reviews. OpenAI — Unsupervised Sentiment Neuron
The system had not been told, directly, what feeling was.
It had not been given a neat little rule:
this is praise
this is disappointment
this is anger
this is delight
It had been asked to continue text.
Character by character.
Review by review.
Mistake by mistake.
And somewhere inside that process, a signal appeared.
Not a human feeling.
Not consciousness.
Not artificial general intelligence.
A representation.
A useful internal feature that tracked something real enough in the text to be used for sentiment.
The model was not taught the label in the usual way.
It found a signal because prediction made the signal useful.
Not magic, not nothing
The sentiment neuron did not make the model human. It did not smuggle artificial general intelligence into an Amazon review model.
But it was more than a curiosity.
The related paper, Learning to Generate Reviews and Discovering Sentiment, described byte-level recurrent language models and reported that, with sufficient capacity, training data, and compute time, the representations learned by these models included disentangled features corresponding to high-level concepts; specifically, the authors found a single unit that performed sentiment analysis. Learning to Generate Reviews and Discovering Sentiment
That is the measured version of the wonder.
A model trained on a simple language objective could learn an internal representation useful beyond the immediate act of prediction.
That matters because the OpenAI bet was never only about one model, one demo, or one result.
The deeper bet was that learning systems, given the right objectives, data, and scale, might discover useful structure that humans had not explicitly programmed.
The sentiment neuron was not the destination.
It was a clue.
The spark needs a furnace

Prediction gave the machine a way to notice. Scaling it would require a furnace.
Until now, this story had moved through people.
A room. A belief. A gathering. A set of careers bent toward a question that sounded too large to hold.
Text becomes pieces.
Pieces become numbers.
Numbers become guesses.
Guesses become corrections.
Corrections become representations.
Representations become signals.
Once prediction could reveal structure, the next question was no longer only philosophical.
It became physical.
How much text? How large a model? How many corrections?
How much compute? How many chips? How much heat?
The spark had moved from the room, into the people, and now into the machine.
But a spark is only a beginning. The furnace would come next.
Prediction had become the machine’s first way of noticing.